
When we are thinking for exporting data in csv, tsv or json format from MongoDB then probably one tool we are using that is mongoexport. This is pretty straight forward and setting up all parameters will get back your desired data in desired format, but in this article we are talking about some situation which shows some limitation of this mongoexport tool.
What is mongoexport?
Mongoexport is a MongoDB database tool and a command-line tool that produces a JSON or CSV export of data stored in a MongoDB instance., which actually shipped with MongoDB package, But 4.4 version onwards, is now released separately from the MongoDB Server and uses its own versioning, with an initial version of 100.0.0.
Scenario
If you do not want full collection export, have a big aggregation query and the return items are so big and you want to capture those output in a csv, json or tsv file then probably you are going to do following things.
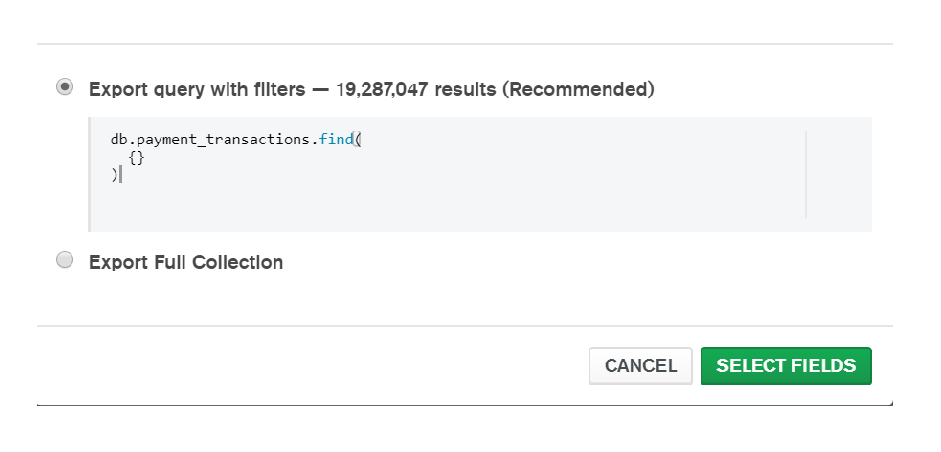
- You probably search for
-qparameter of mongoexport , and you probably find-qor--queryparameter can accept small query not accept big aggregation query. Check the featured image. - Then you will probably go to any mongodb tools like MongoDB compass, in that case also small query accepted, perhaps no way for writing aggregation query. Some other NoSQL GUI have some paid feature to export data in csv, json format.
Probable Solutions
1. Using $out Aggregation stage
You can append $out stage to your aggregation query and produce a new collection and then export all data of that $out collection directly with out making complexities to your mongoexport command.
2. Using The mongo Shell and custom Java script
You can use mongo shell and custom javascript to export whole document in one go, please check $match stage should honor the index.
1. Write your mongodb aggregation query in a javascript file and save it as script.js file. I wrote this sample code and save it to script.js file. Always run this kind of code when there were less load on the cluster and read from secondary and make allowDiskUse: true should be there in your aggregation query.
var count=0;
db.setSlaveOk();
db.getMongo().setReadPref('secondaryPreferred');
//reading from secondary
//db.getMongo().getReadPrefMode();
db.payment_collection.aggregate(
[
{
$match: {
"category":{$in:["TV","APP-MOBILE"] } ,
"orderDate": {
$gte: ISODate("2020-06-18T00:00:00.000+05:30"),
$lt: ISODate("2020-06-18T02:59:59.000+05:30")
}
}
},
{
$project:{
'customerID':1,
'orderId':1,
'amount':1,
'category':1,
'place':1,
'placeID':1,
'nextRetryPaymentDate':{ $dateToString: { format: "%Y-%m-%d--%H:%M:%S", date: "$nextRetryPaymentDate"} },
'parentCategory':1,
'amount':1,
'paymentCount':1,
'orderDate':{ $dateToString: { format: "%Y-%m-%d--%H:%M:%S", date: "$orderDate"} },
'transactionStatus':1,
'refundAmountCount':1,
}
}
],
{
allowDiskUse:true
// very important to use this param
}
).forEach(function(myDoc)
{
var fields=[
'customerID','orderId','amount','category','place','placeID','nextRetryPaymentDate','parentCategory',
'amount','paymentCount','orderDate','transactionStatus','refundAmountCount',
]
// this array for csv file column name
if(count == 0)
{
var str='';
for (key in fields){
str+=fields[key]+','
}
print(str);
}
var value='';
for (key in fields){
value+=myDoc[fields[key]]+','
}
print(value);
// this will write each rows in csv file
count++;
});2. Now open command promt for windows or terminal for linux machine, provided that machine should pre installed MongoDB package. Then type mongo in the shell, will connect local mongodb instance successfully. Then source your script.js file and specify output file path and desired file extension (csv) for the out put file.
mongo "mongodb://username:password@10.10.10.10:27017/db_name?authSource=db_name" C:\Users\kaushik\Desktop\02\script.js > C:\Users\kaushik\Desktop\02\output.csv --quieta) After mongo there is a connection string.
b) Then path of the script.js file path, where I wrote Aggregation query.
c) Output file path output.js.
d) --quiet is preventing printing out mongo shell’s connection message into csv file.
It will export your desired/ expected data to your csv file form your millions of data at source collection.
Conclusion
It may looks like very un optimize way to export the data, but this is the limitation, MongoDB compass will not allow us to use Aggregation query for export the data. Other NoSQL tools also make this paid feature. If you are not taking any premium tool and using community version of MongoDB, then probably it will be the only solution you can leverage it. Developers may use $out statement but do not have the access to create collection, then can not use it. Operations team are reporting to BI with this CSV file you can share easily this script to them. Do not think for making any web based solution (using server side language) to export, it will come out with maximum execution time error. Only mongo shell can accept run the query till you interrupt it. If you have any other solution, then feel free to suggest it in the comment section, please do not share any paid or premium things.

Suggestions